Data Wrangling
How do we do it? 🤔

This diagram is taken from R for Data Science book by Garrett Grolemund and Hadley Wickham, which it is a great resource for learning R. There is a whole community built around it and you could join it and start learning together: R4DS online learning community.
Dataset
To learn and practise how to organise a data we will use a gapminder data set available from gapminder package in R. This dataset is put into R by Jennifer Bryan from a tank of data sets available from Gapminder.
Gapminder is an independent Swedish foundation that helps to promote sustainable global development by collecting and analysiing relevant data and by developing and designing teaching/learning tools. Gapminder was founded in Sweden by Hans Rosling who was a mastermind for distinctive and insightful storytelling about global development using visual animation.
You can see Hans in action in this BBC documentary The joy of Stats available on YouTube.
Gapminder Data
For each of 142 countries, the package provides values for life expectancy, GDP per capita, and population, every five years, from 1952 to 2007.
Before you can take a look at this data set first run the folowing code
# install necessary packages:
install.packages("dplyr", repos = "http://cran.us.r-project.org")
install.packages("ggplot2", repos = "http://cran.us.r-project.org")
install.packages("gapminder", repos = "http://cran.us.r-project.org")
install.packages("DT", repos = "http://cran.us.r-project.org")
#
# have a look at the data through a table
DT::datatable(head(gapminder::gapminder, 10))
💡 Note thet there are 6 columns, each of which we call a variable.
Description: Excerpt of the Gapminder data on life expectancy, GDP per capita, and population by country.
The main data frame gapminder has 1704 rows and 6 variables: - country: factor with 142 levels - continent: factor with 5 levels - year: ranges from 1952 to 2007 in increments of 5 years - lifeExp: life expectancy at birth, in years - pop: population - gdpPercap: GDP per capita
gapminder::gapminder[1:3,]
## # A tibble: 3 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
1st look at the data using the following functions: dim() & head()
library(gapminder)
dim(gapminder)
## [1] 1704 6
head(gapminder, n=10)
## # A tibble: 10 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
Can you tell what each of the two functions does⁉️
Do we have the information about the structure of the data? 🤔 We can examine the structure using str() function, but the output could look messy and hard to follow if the data set is big. 🤪
str(gapminder)
## Classes 'tbl_df', 'tbl' and 'data.frame': 1704 obs. of 6 variables:
## $ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
## $ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
## $ lifeExp : num 28.8 30.3 32 34 36.1 ...
## $ pop : int 8425333 9240934 10267083 11537966 13079460 14880372 12881816 13867957 16317921 22227415 ...
## $ gdpPercap: num 779 821 853 836 740 ...
The dplyr Package
The dplyr provides a “grammar” (the verbs) for data manipulation and for operating on data frames in a tidy way. The key operator and the essential verbs are:
%>%: the “pipe” operator used to connect multiple verb actions together into a pipeline.
select(): return a subset of the columns of a data frame.
mutate(): add new variables/columns or transform existing variables.
filter(): extract a subset of rows from a data frame based on logical conditions.
arrange(): reorder rows of a data frame according to single or multiple variables.
summarise() / summarize(): reduce each group to a single row by calculating aggregate measures.
We can have a look at the data and its structure by using the glimpse() function from the dplyr package.
suppressPackageStartupMessages(library(dplyr))
glimpse(gapminder)
## Observations: 1,704
## Variables: 6
## $ country <fct> Afghanistan, Afghanistan, Afghanistan, Afghanistan, Af…
## $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
## $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, …
## $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854…
## $ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 148803…
## $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.…
🤓💡: Notice how we could prevent display of the messages that appear when uploading the packages by using, in this case, suppressPackageStartupMessages()!
Now we have the dplyr package uploaded, let us learn its verbs. 😇
The pipeline operater: %>%
Left Hand Side (LHS) %>% Right Hand Side (RHS)
x %>% f(…, y)
f(x,y)
The “pipe” passes the result of the *LHS as the 1st operator argument of the function on the RHS.
3 %>% sum(4) <==> sum(3, 4)
%>% is very practical for chaining together multiple dplyr functions in a sequence of operations.
Pick variables by their names: select(),
.png)
starts_with("X")every name that starts with “X”.ends_with("X")every name that ends with “X”.contains("X")every name that contains “X”.matches("X")every name that matches “X”, where “X” can be a regular expression.num_range("x", 1:5)the variables named x01, x02, x03, x04, x05.one_of(x)=> every name that appears in x, which should be a character vector.
👉 Practice ⏰💻: Select your variables
1) that ends with letter p
2) starts with letter co. Try to do this selection using base R.
😃🙌 Solutions:
gm_pop_gdp <- select(gapminder, ends_with("p"))
head(gm_pop_gdp, n = 1)
## # A tibble: 1 x 3
## lifeExp pop gdpPercap
## <dbl> <int> <dbl>
## 1 28.8 8425333 779.
gm_cc <- select(gapminder, starts_with("co"))
head(gm_cc, n = 1)
## # A tibble: 1 x 2
## country continent
## <fct> <fct>
## 1 Afghanistan Asia
of course all of this could be done using base R for example:
gm_cc <- gapminder[c("country", "continent")]
but it’s less intuitive and often requires more typing.
Create new variables of existing variables: mutate()
.png)
It would allow you to add to the data frame df a new column, z, which is the multiplication of the columns x and y: mutate(df, z = x * y).
If we would like to observe lifeExp measured in months we could create a new column lifeExp_month:
gapminder2 <- mutate(gapminder, LifeExp_month = lifeExp * 12)
head(gapminder2, n = 2)
## # A tibble: 2 x 7
## country continent year lifeExp pop gdpPercap LifeExp_month
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779. 346.
## 2 Afghanistan Asia 1957 30.3 9240934 821. 364.
Pick observations by their values: filter()
.png)
There is a set of logical operators in R that you can use inside filter():
x < y:TRUEifxis less thanyx <= y:TRUEifxis less than or equal toyx == y:TRUEifxequalsyx != y:TRUEifxdoes not equalyx >= y:TRUEifxis greater than or equal toyx > y:TRUEifxis greater thanyx %in% c(a, b, c):TRUEifxis in the vectorc(a, b, c)is.na(x): IsNA!is.na(x): Is notNA
👉 Practice ⏰💻: Filter your data
Use gapminder2 df to filter:
1) only European countries and save it as gapmEU
2) only European countries from 2000 onward and save it as gapmEU21c
3) rows where the life expectancy is greater than 80
Don’t forget to use == instead of =! and
Don’t forget the quotes ""
😃🙌 Solutions:
gapmEU <- filter(gapminder2, continent == "Europe")
head(gapmEU, 2)
## # A tibble: 2 x 7
## country continent year lifeExp pop gdpPercap LifeExp_month
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Albania Europe 1952 55.2 1282697 1601. 663.
## 2 Albania Europe 1957 59.3 1476505 1942. 711.
gapmEU21c <- filter(gapminder2, continent == "Europe" & year >= 2000)
head(gapmEU21c, 2)
## # A tibble: 2 x 7
## country continent year lifeExp pop gdpPercap LifeExp_month
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Albania Europe 2002 75.7 3508512 4604. 908.
## 2 Albania Europe 2007 76.4 3600523 5937. 917.
filter(gapminder2, lifeExp > 80)
Reorder the rows: arrange()
is used to reorder rows of a data frame (df) according to one of the variables/columns.
.png)
If you pass
arrange()a character variable, R will rearrange the rows in alphabetical order according to values of the variable.If you pass a factor variable, R will rearrange the rows according to the order of the levels in your factor (running
levels()on the variable reveals this order).
👉 Practice ⏰💻: Arranging your data
1) Arrange countries in gapmEU21c df by life expectancy in ascending and descending order.
2) Using gapminder df
- Find the records with the smallest population
- Find the records with the largest life expectancy.
😃🙌 Solution 1):
gapmEU21c_h2l <- arrange(gapmEU21c, lifeExp)
head(gapmEU21c_h2l, 2)
## # A tibble: 2 x 7
## country continent year lifeExp pop gdpPercap LifeExp_month
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Turkey Europe 2002 70.8 67308928 6508. 850.
## 2 Romania Europe 2002 71.3 22404337 7885. 856.
gapmEU21c_l2h <- arrange(gapmEU21c, desc(lifeExp)) # note the use of desc()
head(gapmEU21c_l2h, 2)
## # A tibble: 2 x 7
## country continent year lifeExp pop gdpPercap LifeExp_month
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Iceland Europe 2007 81.8 301931 36181. 981.
## 2 Switzerland Europe 2007 81.7 7554661 37506. 980.
😃🙌 Solution 2):
arrange(gapminder, pop)
## # A tibble: 1,704 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Sao Tome and Principe Africa 1952 46.5 60011 880.
## 2 Sao Tome and Principe Africa 1957 48.9 61325 861.
## 3 Djibouti Africa 1952 34.8 63149 2670.
## 4 Sao Tome and Principe Africa 1962 51.9 65345 1072.
## 5 Sao Tome and Principe Africa 1967 54.4 70787 1385.
## 6 Djibouti Africa 1957 37.3 71851 2865.
## 7 Sao Tome and Principe Africa 1972 56.5 76595 1533.
## 8 Sao Tome and Principe Africa 1977 58.6 86796 1738.
## 9 Djibouti Africa 1962 39.7 89898 3021.
## 10 Sao Tome and Principe Africa 1982 60.4 98593 1890.
## # … with 1,694 more rows
arrange(gapminder, desc(lifeExp))
## # A tibble: 1,704 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Japan Asia 2007 82.6 127467972 31656.
## 2 Hong Kong, China Asia 2007 82.2 6980412 39725.
## 3 Japan Asia 2002 82 127065841 28605.
## 4 Iceland Europe 2007 81.8 301931 36181.
## 5 Switzerland Europe 2007 81.7 7554661 37506.
## 6 Hong Kong, China Asia 2002 81.5 6762476 30209.
## 7 Australia Oceania 2007 81.2 20434176 34435.
## 8 Spain Europe 2007 80.9 40448191 28821.
## 9 Sweden Europe 2007 80.9 9031088 33860.
## 10 Israel Asia 2007 80.7 6426679 25523.
## # … with 1,694 more rows
Collapse many values down to a single summary: summarise()
.png)
uses the same syntax as
mutate(), but the resulting dataset consists of a single row instead of an entire new column in the case ofmutate().builds a new dataset that contains only the summarising statistics.
👉 Practice ⏰💻: Use summarise():
1) to print out a summary of gapminder containing two variables: max_lifeExp and max_gdpPercap.
2) to print out a summary of gapminder containing two variables: mean_lifeExp and mean_gdpPercap.
😃🙌 Solution: Summarise your data
summarise(gapminder, max_lifeExp = max(lifeExp), max_gdpPercap = max(gdpPercap))
## # A tibble: 1 x 2
## max_lifeExp max_gdpPercap
## <dbl> <dbl>
## 1 82.6 113523.
summarise(gapminder, mean_lifeExp = mean(lifeExp), mean_gdpPercap = mean(gdpPercap))
## # A tibble: 1 x 2
## mean_lifeExp mean_gdpPercap
## <dbl> <dbl>
## 1 59.5 7215.
Let’s %>% all up!
You can try to get into a habit of using a shortcut for the pipe operator

🗣👥 Confer with your neighbours:
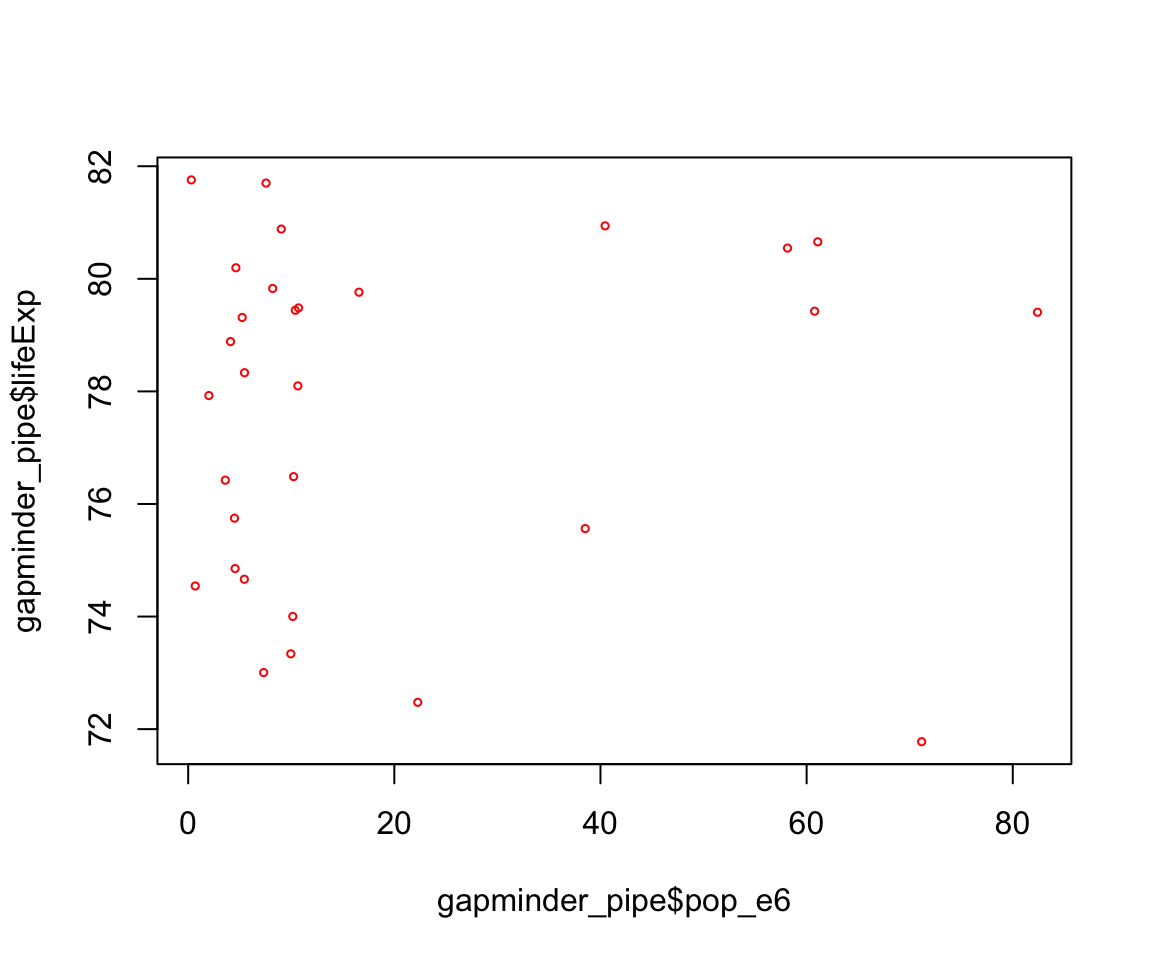
What relationship do you expect to see between population size (pop) and life expectancy (lifeExp)?
Look what this code produces
gapminder_pipe <- gapminder %>%
filter(continent == "Europe" & year == 2007) %>%
mutate(pop_e6 = pop / 1000000)
plot(gapminder_pipe$pop_e6, gapminder_pipe$lifeExp, cex = 0.5, col = "red")
YOUR TURN 👇
Practise by doing the following set of exercises:
1) Install and upload the rattle package and see what it does.
2) Create a new R script file to explore weatherAUS dataset.
i) select() variable: MinTemp, MaxTemp, Rainfall and Sunshine by pipping the dataset into `dplyr::select() function.
ii) produce a summary using base::summary() function of these numeric values.
iii) within this selection filter only those observations where Rainfall >= 1 and save the results into the computer’s memory (ie. save the results as an object).
iv) Try to think of how else you can use other dplyr verbs on this weatherAUS dataset. Write your question first, before embarking on typing the code.
v) Write a short report on what visualisation you think would be interesting to produce for this weatherAUS dataset and why?
Useful Links
Data Transformation with dplyr cheat sheet
© 2019 Tatjana Kecojevic